
Memory-Efficient Full-Volume Inference for Large-Scale 3D Dense Prediction without Performance Degradation
Large-volume 3D dense prediction is essential in industrial applications such as energy exploration and medical image segmentation. However, existing deep learning models struggle to process full-size volumetric inputs at inference due to memory constraints and inefficient operator execution. Conventional solutions—such as tiling or compression—often introduce artifacts, compromise spatial consistency, or require retraining. We present a retraining-free inference optimization framework that enables accurate, efficient, whole-volume prediction without any performance degradation. Our approach integrates operator spatial tiling, operator fusion, normalization statistic aggregation, and on-demand feature recomputation to reduce memory usage and accelerate runtime. Validated across multiple seismic exploration models, our framework supports full size inference on volumes exceeding \(1024^3\) voxels. On FaultSeg3D, for instance, it completes inference on a \(1024^3\) volume in 7.5 seconds using just 27.6 GB of memory—compared to conventional inference, which can handle only \(448^3\) inputs under the same budget, marking a \(13\times\) increase in volume size without loss in performance. Unlike traditional patch-wise inference, our method preserves global structural coherence, making it particularly suited for tasks inherently incompatible with chunked processing, such as implicit geological structure estimation. This work offers a generalizable, engineering-friendly solution for deploying 3D models at scale across industrial domains.
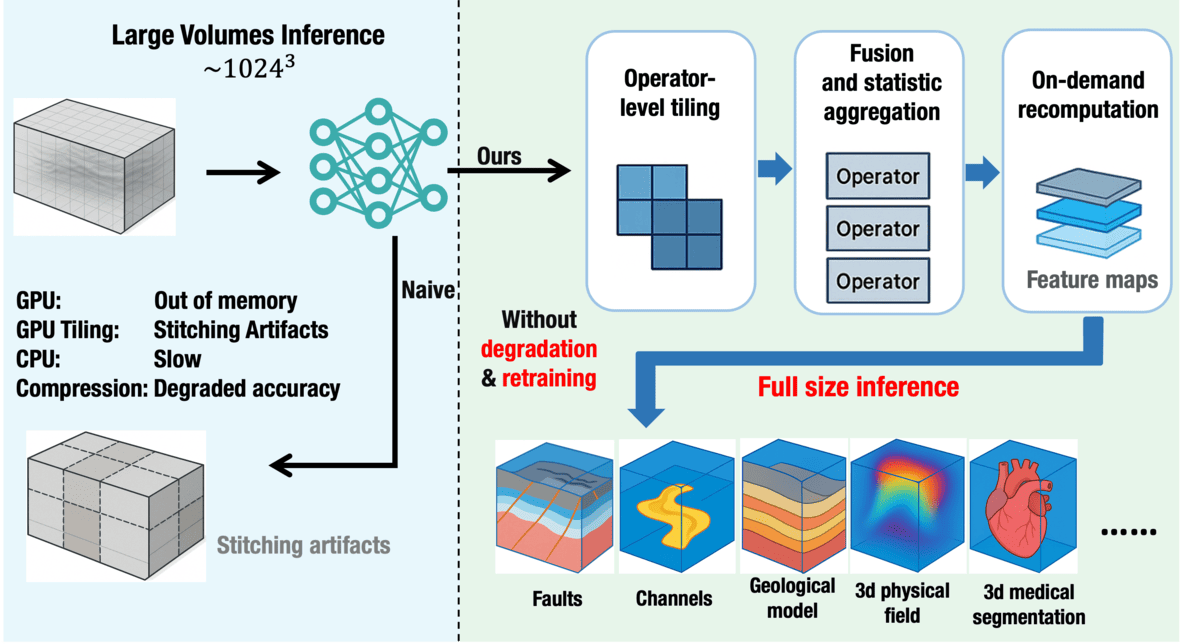
Results
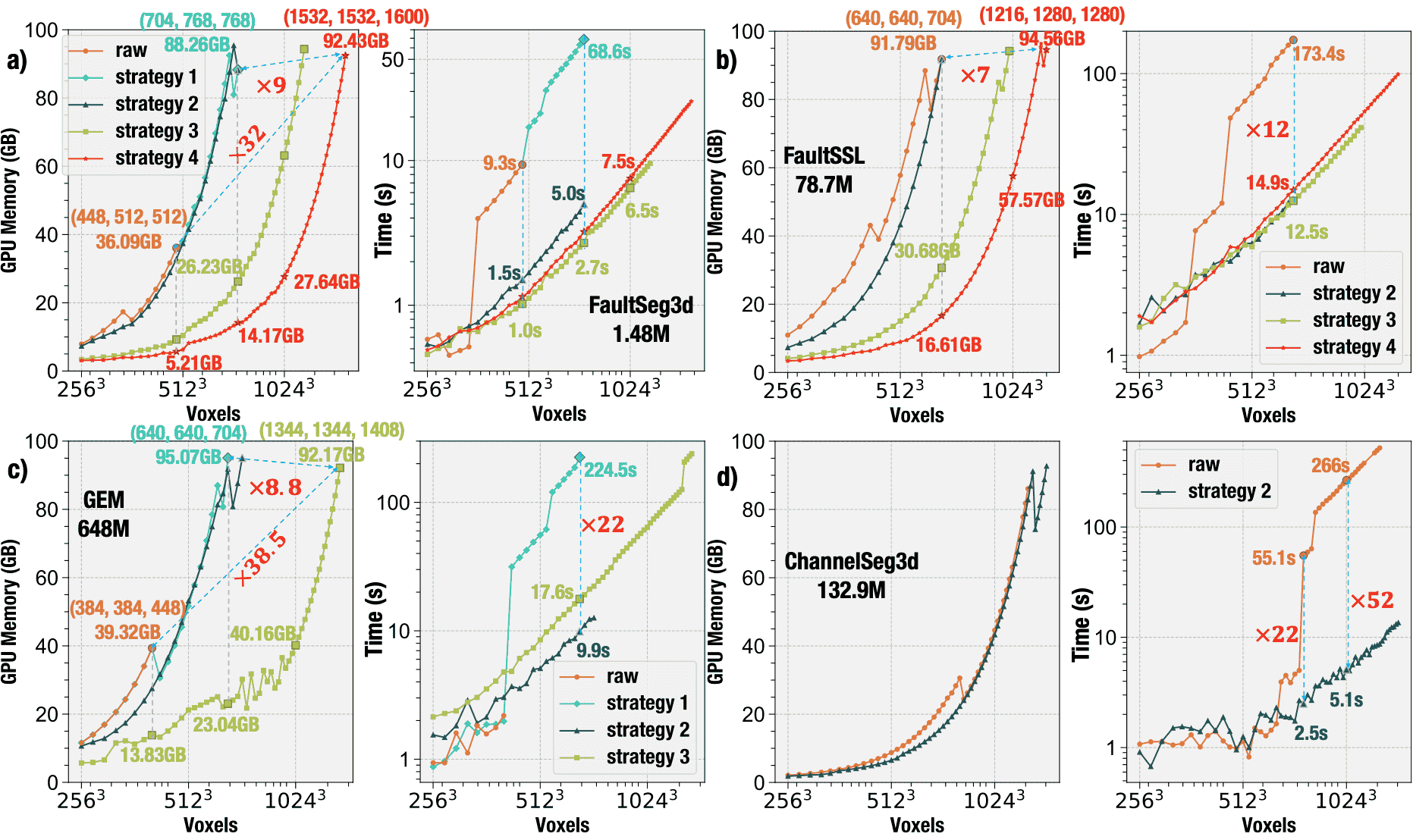
Improving memory and efficiency across representative 3d models.We evaluate the impact of our inference strategies on four representative 3D networks: a) FaultSeg3D, a UNet-style model with skip connections; b) FaultSSL, which combines an HRNet backbone with skip connections; c) GEM, which progressively upsamples predictions without shallow feature reuse; and d) ChannelSeg3D, which generates low-resolution outputs followed by direct interpolation. In all cases, our optimizations—including operator-level spatial chunking, operator fusion, and on-demand recomputation—substantially reduce memory usage and restore near-linear runtime scaling, enabling inference on volumes exceeding \(1024^3\) voxels. For example, ChannelSeg3D achieves a \(52 \times\) speedup at \(1024^3\), and FaultSeg3D reduces memory to just 27.64 GB without sacrificing accuracy. These results hold across different model types and design paradigms, underscoring the generality and practical value of the approach. The numerical comparison can be seen in Table S1.
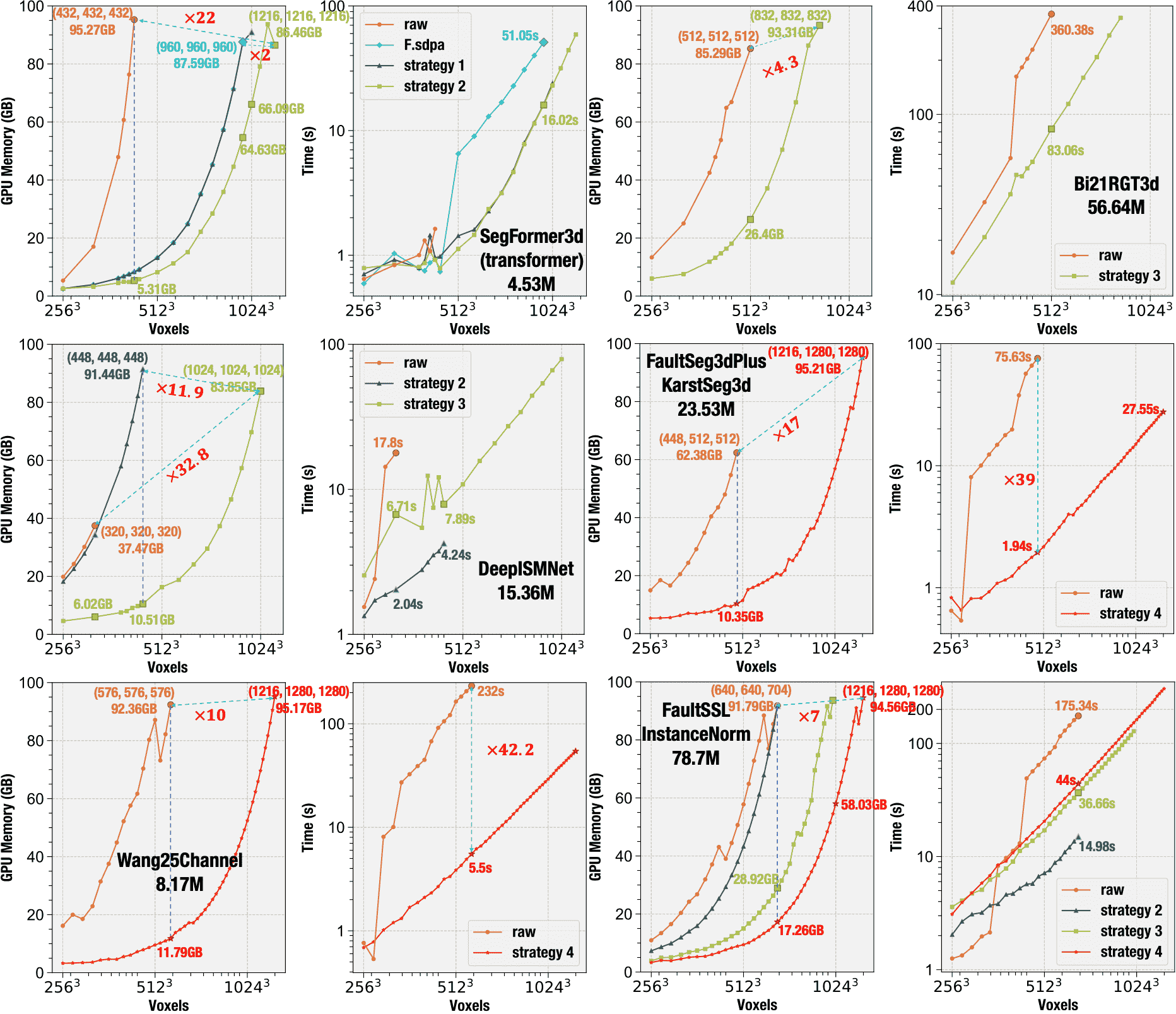
Quantitative comparison of inference efficiency across more representative 3D models. We evaluate GPU memory consumption and inference time for a suite of benchmark volumetric models: SegFormer3d (transformer-based), Bi21RGT3d, DeepISMNet, FaultSeg3dPlus and KarstSeg3d (sharing architecture but trained on different datasets), Wang25Channel, and FaultSSL (with InstanceNorm layers). For each model, we report the GPU memory usage (left) and wall-clock inference time (right) as input size increases. Across all cases, our method consistently reduces memory usage and latency, enabling full-volume inference at high resolution on a single GPU.
Reviewers’ Comments
This paper was unanimously recognized by all three named reviewers (see here for full comments, Or Peer Review File for official version, including our responses):
Reviewer1:
The proposed methods are new and I foresee that they will be used by a lot of relevant fields that rely on 3D dense prediction, e.g., medical imaging, physics field prediction, etc.
I am impressed by the efficacy and performance of the proposed approach. The work is very convincing …
This is the first work I know that specifically addresses the realistic and important issue … This will enable the practical usage and improve the performance of many ML models in the field of seismic interpretation and fields alike. … It has both promising scientific value and engineering significance.
Reviewer2:
I have been applying different DL models on reflection seismic data as large as 1.5 TB in size, and the problem that your submitted manuscript addresses has been one of the fundamental challenges in this area. Providing a solution to reduce memory consumption during model inference—without changing model training parameters-is certainly a research area that deserves attention. As you have clearly mentioned in the manuscript, several strategies have already been proposed, each with its pros and cons.
The pace of new network development is very fast, which makes it difficult to build memory-efficient inference approaches for all of them. Moreover, memory efficiency is usually not the primary goal when new networks are developed; instead, the focus is on improving prediction quality.
I enjoyed reading your manuscript, and I wish you the best of luck moving forward.
Reviewer3:
This paper addresses an important and commonly encountered issue, ……. I myself am a practitioner of ANN segmentation, I recognise the problem and developed or adapted remediation solutions.
An added advantage of the current new approach is that the trained ANN models and input data need no retraining or conditioning, this is of great benefit for the AI community that uses ANNs for segmentation.
The Authors demonstrate …… The results are very convincing and will help the AI community substantially. This paper has therefore a large impact.
All in all, this paper is a welcome contribution to the AI community and brings substantial improvements to the field.
Media Coverage
Our work has been featured and highlighted by several international science and technology media outlets, emphasizing its impact on large-scale 3D data analysis and AI-driven engineering:
Bioengineer.org: Efficient large-scale 3D prediction without performance loss
GeneOnline: Researchers Develop Memory-Efficient Method for Full-Volume Inference in Large-Scale 3D Data Analysis
Code and Data
The source code is publicly available at https://github.com/JintaoLee-Roger/torchseis. Pretrained models used in this study are available on Hugging Face at https://huggingface.co/shallowclose/torchseis-efficiency-infer.
All data and benchmark results (e.g., runtime, memory usage, and error scores) to support the figures and findings of this study are publicly available in the Zenodo repository under the DOI/URL: https://doi.org/10.5281/zenodo.17810071.
Citation
If you find this work useful in your research, please consider citing:
@article{li2026memory,
title={Memory-efficient full-volume inference for large-scale 3D dense prediction without performance degradation},
author={Li, Jintao and Wu, Xinming},
journal={Communications Engineering},
volume={5},
number={1},
pages={20},
year={2026},
doi={10.1038/s44172-025-00576-2},
publisher={Nature Publishing Group UK London}
}